How I Built this Blog with GitHub Discussions
In my last post I covered my decision to use GitHub Discussions as CMS for my posts. I’m going to build it using Next.js, because that’s what I already use a lot, and it has some features which will become quite useful. Let’s get cracking!
Update March 2024: A lot has changed in the meantime, and now I use Next.js’ App Router and React Server Components for server-side rendering. A few things have stayed the same though: I still use GitHub Discussions in the same way (now even with labels) and still revalidate posts via webhooks.
If you are interested in the current implementation, check out the repo: github.com/timomeh/timomeh.de
Update November 2024: I don’t anymore use GitHub Discussions, haha whoops. I’m now using Keystatic, which still stores content on GitHub, but instead as Markdown files in a private repository. Keystatic has an even better writing experience directly in my browser.
Public Repo, Private Posts
Strangers shouldn’t be able to open a new Discussion and poof, it’s visible on my site. That’s my free real estate, not theirs. You could make your Repository private, but I would like it to be public. This way, the Discussion comments could actually be used as comment section.
That’s where GitHub’s “Announcement” format comes in handy. When you create a Discussion category using the Announcement format, only maintainers and admins (that’s me!) can create a new Discussion in this category. Others can still comment on those posts. I created two of those categories, one for actual posts and one for drafts and ideas.
You could also use Issues and a “published” Label to achieve the same security, because only maintainers can set Labels on Issues. Contrary to Issues, Discussion comments are threaded, which I found could be pretty cool.
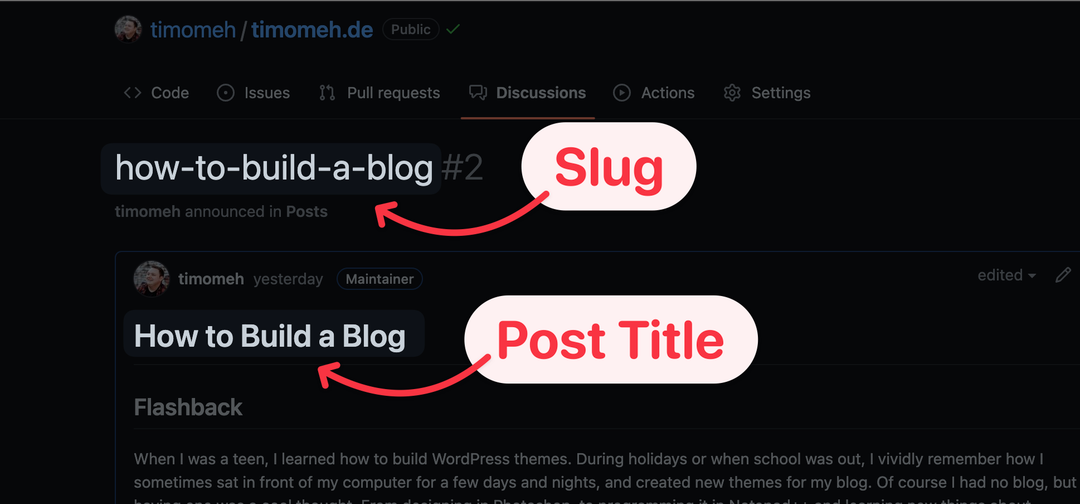
The Problem with Slugs
Like Issues and Pull Requests, Discussions use numbers as user-facing identifier, and don’t have native support for slugs. I want URLs with slugs like /posts/how-to-build-a-blog, not /posts/2. So I’m simply using the Discussion’s title as slug. As post title, I’m using the first heading in the actual post body.
You can see it in action on GitHub.
Loading Posts via the API
GitHub’s API allows unauthenticated requests to public data with a rate limit of 60 requests per hour and IP. That’s not a lot. But if you use a personal Access Token, the rate limit is 5000 requests per hour. That should be enough. I configured the Access Token to only have access to public data, which makes the attack vector pretty insignificant – if that token would ever leak.
GitHub Discussions aren’t available in their REST API. It’s only in their GraphQL API. While I’m not the biggest fan of GraphQL, it’s also not a problem.
Listing all Posts
… is quite straight forward. You can list up to 100 discussions, filtered by the category ID and sorted by created date. It will take a few days until I have 100 posts, but I love implementing pagination because it’s one of the only reasons to use do...while loops.
Fetching a Single Post
Retrieving a single post is the real fun part. Because this is where the next problem with slugs emerges: there’s no API endpoint to get a single Discussion by its exact title, where I store the slug.
My first idea was to just list all posts, what I already do on the List page, and then filter them in JavaScript by an exact title match. I decided on a different solution, but I still think this would be a totally okay solution. I won’t have thousands of posts, and computers are fast.
My other idea, and what I’m using now, is to use GitHub’s Search API. It allows you to find Discussions with a title which includes a search term. I found some people online saying that the search results aren’t reliable, but I found it works without any issues.
This means it could return multiple results, when the slugs are very similar, like my-post and my-post-part-2. But again, we can just find an exact title match using JavaScript.
async function getBlogPost(slug) {
const { search } = await api(
`query postBySlug($search: String!) {
search(
query: $search
type: DISCUSSION
first: 100
) {
edges {
node {
... on Discussion {
title
createdAt
body
number
category {
id
}
}
}
}
}
}`,
{ search: `"${slug}" in:title repo:${owner}/${repo}` }
)
const post = search.edges.find((result) => {
const discussion = result.node
const isMatchingSlug = discussion.title === slug
const isPostsCategory = discussion.category.id === POSTS_CATEGORY_ID
return isMatchingSlug && isPostsCategory
})?.node
return post
}
Side note: You see those node and edges in the code snippet above? That’s one reason why I’m not a big fan of GitHub’s GraphQL API.
I spare you with the details of turning the Markdown body into HTML using remark and rehype because I hated it. But if you’re interested, everything related to data fetching and transforming is located in the lib/blog.ts file in my repo.
Silly Feature: Custom Published Date
If we can find Discussions which include the slug in their title, we could in theory add more information into the title. Nothing crazy, it shouldn’t conflict with the slug itself, but I added a small feature that you can optionally add a custom published date into the title, using the format some-slug YYYY-MM-DD.
I could use this if I ever want to show a different published date than the actual Discussion’s creation date. Maybe it will come in handy some day.
Caching is Next.js’ Best Friend
One thing I hated about my last site was that I had to rebuild it for every change. I don’t want to deal with that anymore. But it also would be unnecessary to call GitHub’s API on every request. The site would be slow, unresponsive when GitHub’s API is flaky, and a chaos monkey could flood me with requests and exceed my rate limit.
Next.js’ Incremental Static Generation to the rescue: it generates the page on the server and caches it, so the next request is served from cache.
// posts/[slug].ts
export async function getStaticPaths() {
return {
paths: [], // don't pre-render anything during build time
fallback: 'blocking',
}
}
export async function getStaticProps(context) {
const post = await getBlogPost(context.params.slug)
if (!post) {
return { notFound: true }
}
return {
props: { post },
revalidate: false // cache it forever (default)
}
}
You could set revalidate: 60 and Next.js would refetch the data if the cache is older than 60 seconds – or any cache time you want to set. But we can do better.
Using Webhooks to Regenerate Pages On Demand
On-demand Revalidation is a Next.js feature on top of Incremental Static Generation, which allows to you regenerate a specific page only when it’s necessary.
All you need to do is to create an API Route, run res.revalidate(path), and let GitHub send a Webhook to this API Route every time a Discussion is created or updated. All affected pages will immediately be regenerated, the site is fast, and you only make a few requests every now and then. API Rate Limits won’t be an issue at all.
// api/github-webhook.ts
export default async function handler(req, res) {
const webhooks = new Webhooks({
secret: process.env.GITHUB_WEBHOOK_SECRET,
})
// Verify that it's actually GitHub sending the Webhook
const signature = req.headers['x-hub-signature-256']
const verified = await webhooks.verify(req.body, signature)
if (!verified) {
res.status(401).json({ hint: 'Unverified' })
}
// Verify that it's only related to Discussions
if (!data.discussion) {
res.status(401).json({ hint: 'Not a discussion event' })
}
// Verify that it's the correct Posts Category
if (data.discussion.category.node_id !== POSTS_CATEGORY_ID) {
res.status(200).json({ hint: 'Only Blog Post Category allowed.' })
}
// New Post: regenerate the List of Posts
if (data.action === 'created') {
await res.revalidate('/posts')
res.status(200).json({ hint: 'Revalidated pages' })
return
}
// Updated Post: regenerate the Post and the List of Posts
if (data.action === 'edited') {
const { slug } = parseDiscussionTitle(data.discussion.title)
await res.revalidate('/posts')
await res.revalidate(`/posts/${slug}`)
res.status(200).json({ hint: 'Revalidated pages' })
return
}
}
Adding Comments
I didn’t add comments yet, but maybe I’ll add them in the future. giscus looks like the perfect fit to embed the Discussion’s comment section below a post.
Feels Good
I’m really happy with this solution. For the previous post, I could fix some typos on my phone last evening and it was immediately updated on my site. The Next.js site is hosted on Vercel’s free tier, I still have my own minimalistic design, with a free CMS which I don’t need to host, maintain and update.
You can find all code in my timomeh.de GitHub Repository.
Comment: [email protected]